2025年2月,昆仑万维天工团队发布了首款中文逻辑推理大模型Skywork-o1。此后,团队持续钻研、不断优化,于4月13日重磅推出全新升级的Skywork-OR1(Open Reasoner 1)系列模型。
该系列模型在同等参数规模下,推理性能达到业界领先水平,成功突破了大模型在逻辑理解和复杂任务求解方面长期存在的能力瓶颈。更值得一提的是,Skywork-OR1选择全面开放、免费供用户使用,以完全开源的形式回馈开发者社区,充分彰显了天工团队坚持推动AI技术开源发展的决心。
此次开源的Skywork-OR1系列包含三款高性能模型:
- Skywork-OR1-Math-7B:专注于数学领域的专项模型,在代码能力方面同样表现出色。
- Skywork-OR1-7B-Preview:融合了数学与代码能力,是一款兼具通用性与专业性的通用模型。
- Skywork-OR1-32B-Preview:作为旗舰版本,面向更高复杂度的任务,具备更强的推理能力。
Skywork-OR1系列采用了业界透明度极高的开源策略。与其他前沿开源推理模型仅开放模型权重不同,昆仑万维天工团队全面开源了模型权重、训练数据集以及完整训练代码。目前,所有资源均已上传至GitHub和Huggingface平台。同时,配套的技术博客也已在Notion平台发布,其中详细阐述了数据处理流程、训练方法以及关键技术发现,为社区开发者提供了完全可复现的实践参考。
需要注意的是,目前Skywork-OR1-7B和Skywork-OR1-32B的能力还在持续提升中。两周内,天工团队将会发布这两个模型的正式版本,并推出更为系统详尽的技术报告,进一步分享在推理模型训练中的宝贵经验与深刻洞察。团队相信,这种全方位的开源策略,将有力推动整个AI社区在推理能力研究方面共同进步。
Skywork-OR1系列开源地址
- GitHub:https://github.com/SkyworkAI/Skywork-OR1
- Huggingface:https://huggingface.co/Skywork
模型开源与评测
在模型评测环节,Skywork-OR1系列模型引入了avg@k作为核心评估指标。该指标用于衡量模型在进行k次尝试时成功解决问题的平均表现。与传统的pass@k指标仅关注“是否至少一次成功”不同,avg@k能够更细致地捕捉模型在多轮生成过程中的稳定性以及整体推理能力,从而更全面、精准地反映模型的真实性能水平与实用价值。
数学推理任务表现
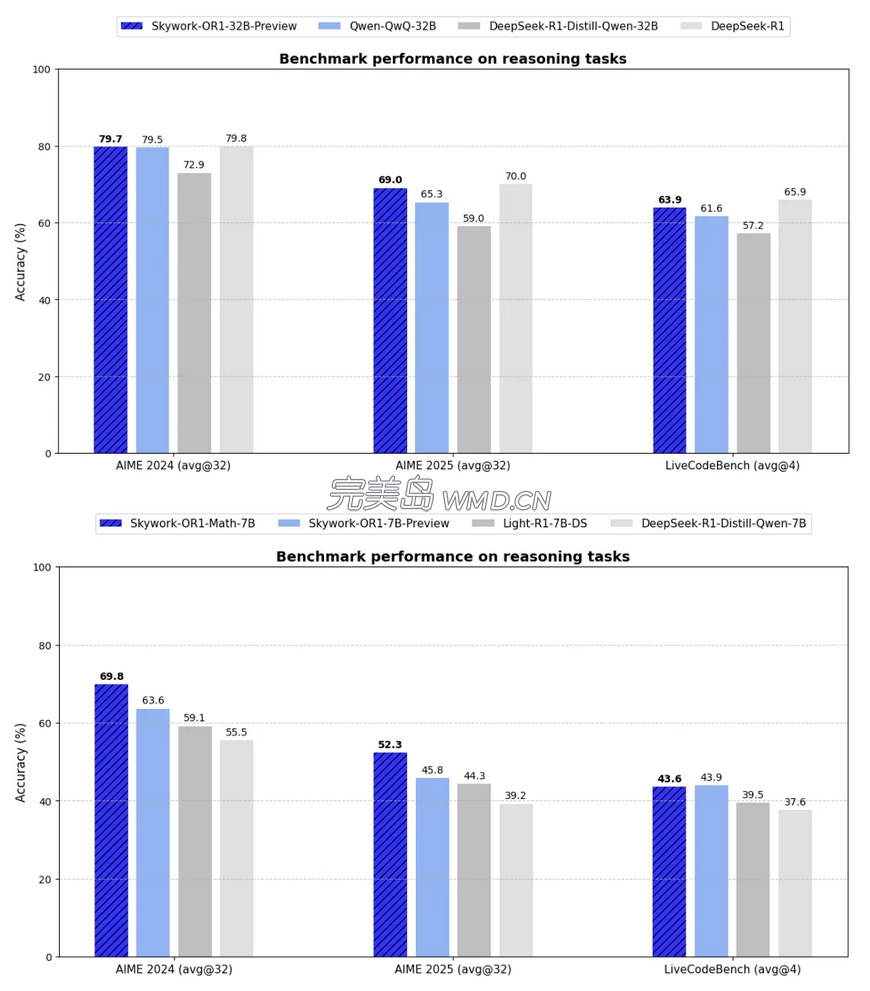
- 通用模型Skywork-OR1-7B-Preview和Skywork-OR1-32B-Preview在AIME24与AIME25数据集上,均取得了同参数规模下的最优成绩,充分展现出强大的数学推理能力。
- 针对数学场景深度优化的专项模型Skywork-OR1-Math-7B,在AIME24和AIME25上分别斩获69.8与52.3的高分,大幅超越当前主流7B级别模型,有力验证了其在高阶数学推理任务中的专业优势。
- Skywork-OR1-32B-Preview在所有benchmark上均超越了QwQ-32B,并且在难度更高的AIME25上基本与R1持平。
竞赛编程任务表现
- 通用模型Skywork-OR1-7B-Preview与Skywork-OR1-32B-Preview在LiveCodeBench数据集上,均达到了同等参数规模下的最优性能。
- Skywork-OR1-32B-Preview表现尤为突出,其代码生成与问题求解能力已接近DeepSeek-R1(参数规模高达671B)。该模型在大幅压缩体量的同时,实现了卓越的性价比,充分彰显了天工团队训练策略的先进性。
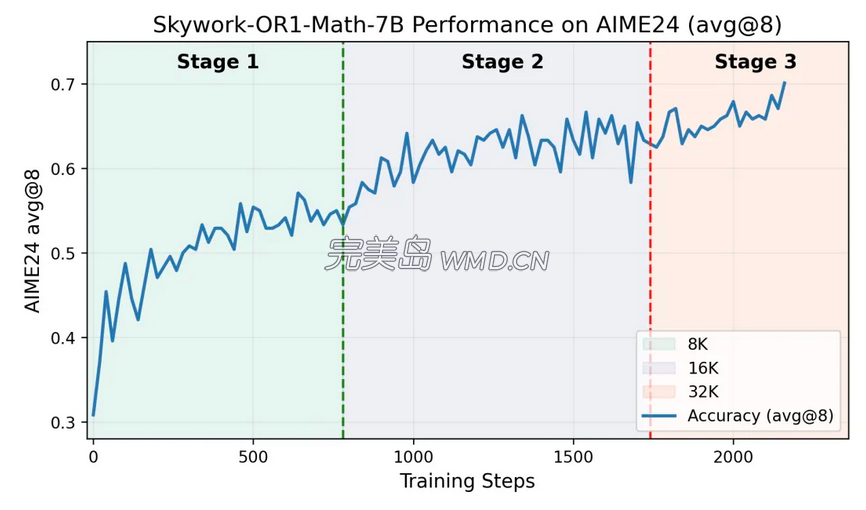
Skywork-OR1-Math-7B表现十分亮眼。作为一款专注于数学推理能力的7B参数模型,它通过多阶段GRPO训练,在复杂数学问题上取得了卓越成果,同时在代码任务上也展现出较强的泛化能力。从该模型在AIME24上的训练准确率曲线可以清晰看到,在多阶段训练过程中,其性能呈现稳定提升态势。最终,Skywork-OR1-Math-7B在AIME24和AIME24上分别达到69.8%和52.3%,超越了OpenAI-o3-mini (low),达到当前尺寸SOTA性能。值得注意的是,尽管该模型在训练过程中未专门针对代码能力进行优化,但在代码评测基准Livecodebench上,成绩从37.6%提升到43.6%,相比基线模型有显著提升,这也表明天工团队的训练方法具备良好的领域泛化性。
技术亮点
Skywork-OR1系列模型在数学推理与代码生成任务上实现显著性能突破,这得益于天工团队在模型后训练阶段长期的自研积累与技术深耕。更多实验设置可参考技术博客,以下为Skywork-OR1的核心技术要点:
数据选择和预处理
Skywork-OR1构建了高质量数学和代码数据集,用于强化学习以提升模型在数学和代码领域的推理能力。团队采用严格筛选和评估机制,构建高质量强化学习训练集,主要依据可验证性(Verifiable)、正确性(Correct)与挑战性(Challenging)三个标准进行初步数据筛选,剔除无法自动验证的证明类题目、有误题目、和缺少unit test的代码问题。数学领域主要依赖NuminaMath-1.5(含约89.6万题),选用如AIME和Olympiads等较难子集,并补充了如DeepScaleR、Omni-MATH、AIME 1983 - 2023难题来源,总计约11万道数学题目。在代码领域,以LeetCode和TACO数据为主,保留了单元测试完整、验证通过的问题,并进行向量级语义去重,最终获得13.7K条高质量代码问题。
数据过滤
为避免“全对”或“全错”现象对策略学习无效,每道题进行了多轮采样并验证答案,并基于模型表现过滤难度极端的题目。在数据收集和整理过程中,发现很多数学题存在不完整或格式不正确的问题。为进一步提升数学数据质量,通过人类评审结合LLM自动判题机制,对语义不清、信息不全、格式错误或含有无关内容的题目进行清理。使用LLM-as-a-Judge的方式,对每题进行32次打分,设定投票门槛,剔除约1 - 2K道质量不达标的数学题。整体流程体现了团队在数据质量、模型难度匹配与效率间的深度平衡。
模型训练优化
- 训练时数据优化
- Offline & Online Filtering:对采集的数据实施双重过滤机制。训练前(离线过滤),利用待训练模型对数据进行正确性评估,精确剔除正确率为0(完全错误)和1(完全正确)的样本,确保初始训练集具有学习价值。训练过程中(在线过滤),每个epoch开始时,自动将上一个epoch模型已完全掌握(全部答对)的数据从训练集中移除。这种渐进式过滤机制确保模型始终面对具有学习挑战的数据,最大化有效梯度比例,提高训练效率和模型性能。
- Rejection Sampling:在GRPO训练实施过程中,引入精细化样本筛选机制,动态剔除当前训练步骤中采样正确率为0或1的样本。这些边界样本的policy loss为零,在包含entropy loss或KL loss的训练设置下,会导致非policy loss的比重不当增加,引发训练不稳定性。通过实时rejection sampling,有效维持各损失函数间的原始比重,确保训练过程的稳定性和收敛质量。
- 训练Pipeline优化
- Multi Stage Training:整体训练流程采用迭代增加上下文窗口长度(seq_len)的策略,将训练过程分为多个阶段。先在较小窗口下训练,促使模型学会在有限token内高效完成任务,提高token效率;随后逐步扩展窗口大小,迭代增加生成长度,使模型逐渐掌握更复杂的长链思维能力。实验证明,多阶段训练能大规模缩短训练时间,同时完全保持模型的长度扩展能力。这种渐进式训练方法既确保计算效率,又不牺牲模型在复杂问题上的推理深度。
- Truncated Advantage Mask:在多阶段训练初期,由于上下文窗口限制,复杂问题的回答可能被截断。关于是否使用这些样本进行训练,研究了两种处理策略:Adv-Mask Before(计算优势前排除截断样本)和Adv-Mask After(计算后将截断样本优势置零)。实验表明,这些策略能缓解响应长度衰减,但在训练框架下,即使不屏蔽截断样本,模型也能有效适应长度限制并在进入下一阶段时迅速提升性能。虽然屏蔽有助于保持更好的test-time scaling能力,但在最大长度评估下并未有端到端性能提升,证明多阶段训练方法具有较强鲁棒性。
- 训练时模型探索
- Higher Temperature:在强化学习采样时,采用较高的采样温度τ = 1.0(相比常见的0.6),以增强模型的探索能力。在GRPO框架下,低温度采样会导致模型迅速进入低熵状态,策略更新过度集中于特定token。相比之下,τ = 1.0维持了更高的群组内多样性,既保证足够的正确样本提供学习信号,又允许模型探索更广泛的解决路径,在对比实验中展现出更优性能表现。
- Enhancing Internal Training Diversity:通过精细的数据过滤、增加批量大小和减少数据重复使用等方法,增加数据多样性,间接增加训练内在多样性,从源头上防止模型优化到单一输出方向。这些措施使模型能在更长时间内维持较高的熵值,实现保持较高探索性的同时达到同等准确率的优势效果,有效避免过早陷入局部最优。
- Adaptive Entropy Control:提出自适应熵控制(Adaptive Entropy Control)方法作为额外的探索引导机制。传统的固定系数熵损失对训练数据和超参数极为敏感,此前调整好的参数在后续切换数据或修改其他超参数的实验中可能导致训练崩溃。结合多样性控制策略,采取更为谨慎的熵控制方法:只有当熵值下降到预设阈值以下时才提供熵增加的鼓励。通过设定目标熵值并动态调整熵损失系数,专注于防止熵值降至特定下界,同时最小化对正常训练轨迹的干扰。整体而言,更侧重在内在层面增加训练多样性,减少人为对训练进程的干扰,保证训练的可扩展性。
- 训练Loss优化
- No KL loss:近期不少从base模型开始训练的推理模型,因base模型输出模式较差,放弃了KL损失项。但对于基于精细构造的cold start SFT模型进行训练的情况,相关研究较少。在实验中发现,即使从高质量SFT模型出发,KL损失项仍会限制模型性能进一步提升,强制将actor模型约束在原始分布附近。因此,除特定阶段外,所有公开发布的Skywork-OR1系列模型均未使用KL损失项,使模型能够更充分地探索和优化推理能力。
- Token-level policy loss:为消除原始GRPO中对生成长度的隐性偏好,移除策略损失中的长度归一化项,并将损失在训练批次内的所有token上进行平均,提升优化过程的一致性与稳定性。
更多技术细节和实验对比可参照技术博客:https://capricious-hydrogen-41c.notion.site/Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680,或持续关注后续发布的技术报告。
坚定开源
自2023年起,昆仑万维便坚定地投身于开源大模型事业,回馈开发者与整个行业。截至目前,在Hugging Face上已上传22个模型、6个数据集,收获了开发者社区的广泛好评。2025年开源的Skywork-R1V多模态视觉推理模型、SkyReels-V1面向AI短剧创作的视频生成模型、Skywork-o1推理模型,以及2024年开源的Skywork-Reward奖励模型,不仅在Hugging Face上下载数据表现优异,开发者讨论度和模型热度也持续高涨。
当前,全球人工智能领域竞争愈发激烈,焦点逐渐从基础模型能力转向推理能力的比拼。AI大模型能否有效模拟人类思维过程,具备逻辑推理和复杂任务求解能力,已成为衡量技术先进性与通用智能潜力的关键指标。在此背景下,为打破科技巨头对核心AI大模型技术的垄断,推动技术自主可控发展,中国多家企业积极投身开源大模型生态建设。未来,昆仑万维将继续秉持“All in AGI与AIGC”战略以及“实现通用人工智能,让每个人更好地塑造和表达自我”的使命,持续加大在通用大模型、开源框架和推理能力提升等方向的研究投入,努力在全球AI技术浪潮中抢占先机、打造竞争优势。